
去年年底馬斯克的 FSD V12 全球直播,重新訓(xùn)練的系統(tǒng)完全沒有給這位科技頂流一點面子。
在全球觀眾的見證下,特斯拉試圖闖一次陣仗最大的紅燈,來告訴所有人:端到端自動駕駛,其實沒有那么容易。
「是技術(shù)進(jìn)步,還是一意孤行」,在一個傳統(tǒng)分模塊的技術(shù)棧面前顯而易見的 Bug 出現(xiàn)了之后,也就有了討論的空間。
但是,好在 FSD V12 并沒有停滯不前,這些討論并不會傳到技術(shù)開拓者的耳朵里。
FSD V12.3 發(fā)布,馬斯克宣布北美車主可以試用一個月。
事情開始發(fā)生變化,由「端到端是一條死路」,變成了「路況還是簡單,有本事到國內(nèi)來試試」。
進(jìn)入 2024 年,國內(nèi)廠商突然然開始著手宣傳端到端,各大廠商都有意無意地透露,自己正在這個方向上押重注。
- 3 月 17 日,在汽車百人會上,二線智能駕駛廠商元戎啟行突然宣布,元戎啟行是國內(nèi)第一家能夠?qū)⒍说蕉四P统晒ι宪嚨娜斯ぶ悄芷髽I(yè);
- 4 月 24 日 ADS 2.0 升級為乾崑 3.0,技術(shù)轉(zhuǎn)向 GOD/PDP 網(wǎng)絡(luò)全新架構(gòu),對外稱是端到端架構(gòu);
- 5 月 20 日,小鵬汽車舉辦了以「開啟AI智駕時代」為主題的AI DAY發(fā)布會,宣布端到端大模型已經(jīng)量產(chǎn)上車;
- 5 月 22 日,傳出消息,小米汽車原圖森未來首席科學(xué)家王乃巖即將帶領(lǐng)團(tuán)隊加入小米汽車,負(fù)責(zé)端到端自動駕駛團(tuán)隊,而王乃巖樂于表達(dá),在知乎上也曾多次抨擊端到端自動駕駛;
就像 2021 年 BEV 浪潮一樣,各大廠商再次在自動駕駛路線上達(dá)成了一致。
那么什么是端到端自動駕駛,先進(jìn)在何處,真的能幫助我們獲得更好的自動駕駛體驗嗎?
01 什么是端到端自動駕駛
經(jīng)典的自動駕駛系統(tǒng)有著相對統(tǒng)一的系統(tǒng)架構(gòu):
- 探測(detection);
- 跟蹤(tracking);
- 靜態(tài)環(huán)境建圖(mapping);
- 高精地圖定位;
- 目標(biāo)物軌跡預(yù)測;
- 本車軌跡規(guī)劃;
- 運動控制。
幾乎所有的自動駕駛系統(tǒng)都離不開這些子系統(tǒng),在常規(guī)的技術(shù)開發(fā)中,這些模塊分別由不同的團(tuán)隊分擔(dān),各自負(fù)責(zé)自己模塊的結(jié)果輸出。
這樣的好處是,每一個子系統(tǒng)都能夠有足夠好的可解釋性,在開發(fā)時能夠獨立優(yōu)化。
與此同時,為了保證整體自動駕駛的性能,每一個模塊都需要保證給出穩(wěn)定的表現(xiàn)。
如果將這些系統(tǒng)簡單分為兩部分,可以是感知系統(tǒng)和規(guī)劃控制系統(tǒng):
其實最主要的特征是:感知得到結(jié)果之后,將結(jié)果傳遞給規(guī)劃控制系統(tǒng)。
為了讓系統(tǒng)表現(xiàn)足夠好,其實暗含了兩個條件:
- 感知的結(jié)果足夠正確
- 規(guī)劃控制獲得的信息足夠豐富
很遺憾,這兩條都難以保證,為何?
規(guī)劃控制所有從感知得到的信息,都是感知工程師基于現(xiàn)有的資源定義好的,這里的資源包括:標(biāo)注的能力、獲取相應(yīng)數(shù)據(jù)的能力,甚至工程師們對駕駛的理解。
舉一個非常簡單的例子,一般來說我們開車時候發(fā)現(xiàn)前車打轉(zhuǎn)向燈,我們會相對開始警覺,并且給前車足夠的空間進(jìn)入本車道,但是由于團(tuán)隊限于資源,并沒有識別前車轉(zhuǎn)向的信號。
這個「前車打開轉(zhuǎn)向燈」的信息,對于規(guī)劃控制來說,它就是丟失了。
「因此發(fā)現(xiàn)轉(zhuǎn)向燈信號,并且提前做出反應(yīng)」,這個策略就成了一個不可能完成的任務(wù)。
這就引出了模塊化自動駕駛的弊端:信息的有損傳遞。
下游任務(wù)得到的信息是不充分的,就相當(dāng)于有兩個駕駛員,其中主駕眼睛被蒙住,只負(fù)責(zé)操作;另一個坐在副駕駛,由他來告訴主駕駛前方發(fā)生了什么。
而信息的傳遞方式是兩個駕駛員都能理解的,我們可以稱之為:信息的顯式表達(dá)。
舉個例子,駕駛的語境中前方目標(biāo)的識別,就是高度抽象的顯式表達(dá),一輛車被抽象成、速度、位置、尺寸、加速度等。
這種表達(dá)是人為用經(jīng)驗抽象出來并且傳遞給下游。
但是「被誤解是表達(dá)者的宿命」,人和人之間的信息傳遞一定是有損的,所以這種開車方式很難達(dá)到非常好的體驗。
優(yōu)秀的分模塊系統(tǒng)就相當(dāng)于兩個駕駛員有了足夠的駕駛默契,但是絕對不能與一個有足夠駕駛經(jīng)驗的司機對比。
既然信息顯示表達(dá)傳遞會有損耗,那該怎么做?
這里有個概念是:信息的隱式表達(dá)。
我們常常看到一些論文提到 Feature 層,這是一些信息在神經(jīng)網(wǎng)絡(luò)中的某一層的特征表達(dá),是在訓(xùn)練過程中,網(wǎng)絡(luò)自行學(xué)到的重要信息。但是這些信息不是靠人為定義確定的,我們的經(jīng)驗并不能完全理解,但是神經(jīng)網(wǎng)絡(luò)能夠理解,自動選擇重要的信息。

回到自動駕駛語境中,那就是如果信息的表達(dá)是有損耗的,那么就不表達(dá)了,直接將用神經(jīng)網(wǎng)絡(luò)里的信號與下游對接起來。
這其實就是 CVPR 2023 年 Best Paper UniAD 的思路:分模塊端到端。
分模塊端到端
模塊與模塊之間的信息傳遞不再是開發(fā)工程師能夠直接閱讀并且理解的內(nèi)容,而是直接將幾個模塊連接起來,然后在訓(xùn)練中進(jìn)行全局優(yōu)化。
由此產(chǎn)生了區(qū)別于傳統(tǒng)自動駕駛技術(shù)棧最重要的結(jié)構(gòu)特征:全局可導(dǎo)并且可以全局訓(xùn)練。
UniAD
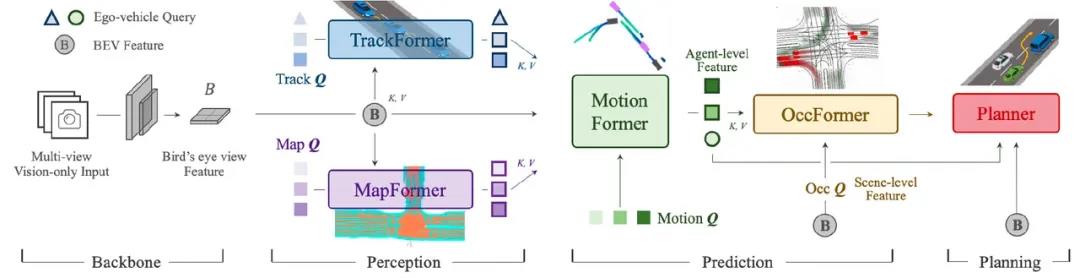
這里我們簡單看一下UniAD 的思路,從結(jié)構(gòu)上看,如果不考慮各模塊之間的連接,可能會認(rèn)為這就是一個傳統(tǒng)的大力飛磚,所有的模塊都用 Transformer 進(jìn)行改造的系統(tǒng)。因為依然可以很明顯的看到 BEV freature 層、MapFormer(建圖)、TrackFormer(跟蹤)等模塊。
但是,其實最重要的改進(jìn)并不是如此,而是各個模塊之間的連接方式,并不是像我們傳統(tǒng)技術(shù)棧一樣,用初級工程師甚至駕駛員完全能夠理解的方式進(jìn)行連接的,而是通過神經(jīng)網(wǎng)絡(luò)的方式進(jìn)行連接。
當(dāng)然由于開環(huán)評測方式(并不是實際運行結(jié)果,與環(huán)境并沒有交互)過于單一。業(yè)內(nèi)也有學(xué)者對其提出批評,認(rèn)為由于 UniAD 主要在 Nuscenes 上進(jìn)行開環(huán)評測,導(dǎo)致大部分的軌跡,模型只要輸出合適的直行命令即可獲得較好的結(jié)果,并且甚至還設(shè)計了一個新的模型,將感知結(jié)果完全丟失,只留下自車和周圍車輛的軌跡,也能獲得不錯的結(jié)果。
VAD
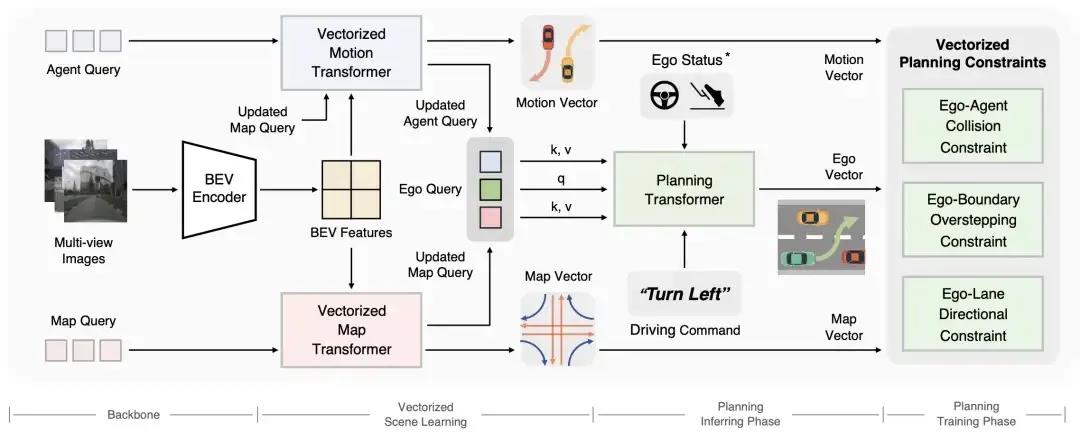
這篇論文發(fā)表在 2023 年的 ECCV 上,相較于 UniAD ,摒棄了傳統(tǒng)技術(shù)棧中的柵格化表征,對整個駕駛場景進(jìn)行矢量化建模,同樣與 UniAD 一致,VAD 基于統(tǒng)一的 Transformer 結(jié)構(gòu)。
- 動態(tài)目標(biāo)信息由 Vectorized Motion Transformer 提取,實現(xiàn)動態(tài)目標(biāo)檢測和矢量化的軌跡預(yù)測;
- 靜態(tài)地圖由 Vectorized Map Transformer 提取;
- Planning Transformer 以隱式的動靜態(tài)場景特征作為輸入,并且獲得相應(yīng)的規(guī)劃信息。
從結(jié)構(gòu)來看,OCC 的模塊被完全拋棄了。
對此論文中也有解釋,OCC 的模塊一定程度上作為后處理兜底的任務(wù),具有較大的算力開銷,而 VAD 選擇在訓(xùn)練階段引入更多約束,降低對后處理兜底的需求。
于此同時,VAD 也在 Carla(一種被學(xué)界廣泛使用的自動駕駛模擬器)中進(jìn)行了評測,也獲得了非常好的結(jié)果。
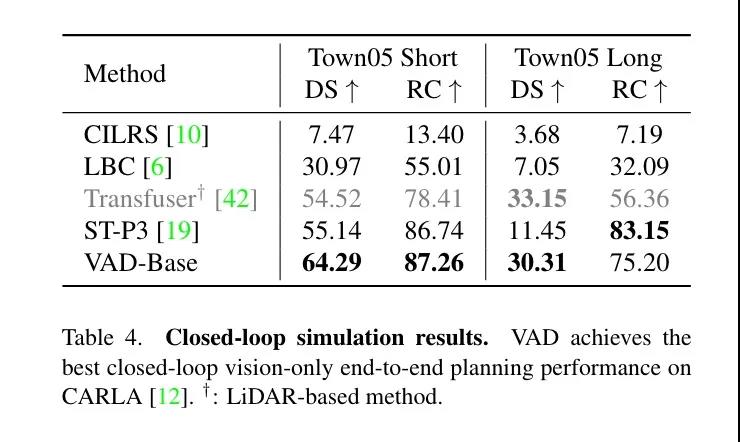
從這兩篇論文中我們不難看出,學(xué)界對于端到端自動駕駛的態(tài)度應(yīng)該是可連接并且全局可以進(jìn)行共同優(yōu)化訓(xùn)練的端到端,而非一個完全的純黑盒網(wǎng)絡(luò),還是從原有的自動駕駛技術(shù)棧進(jìn)行改進(jìn)而來,這實際上與大模型無關(guān),也與 nWorld Model 也并沒有產(chǎn)生實際的聯(lián)系。
那么既然定義清楚了,業(yè)內(nèi)是否都有必要切換呢?切換的難度在什么地方?
02 端到端自動駕駛會帶來什么
全局可導(dǎo)并且全局優(yōu)化是端到端結(jié)構(gòu)上的特點,這種特點能帶來什么呢?
「Scaling Law」
這是一個非常流行的詞匯,從 ChatGPT 3.5 橫空出世,震驚之余人們總結(jié)出來的經(jīng)驗,通俗的說法即:數(shù)據(jù)驅(qū)動,大力出奇跡。
這也是 OpenAI 奉為圭臬的開發(fā)準(zhǔn)則,事實證明這條路確實能夠產(chǎn)生出來目前最優(yōu)秀的人工智能產(chǎn)品,ChatGPT4、Sora,都遵循這條規(guī)則。
而自動駕駛現(xiàn)有的技術(shù)棧每個模塊之間是不可連接的,每個模塊之間是靠人為和規(guī)則進(jìn)行連接的,無法完全靠數(shù)據(jù)進(jìn)行全局訓(xùn)練,那么 Scaling Rule 至少在目前在自動駕駛界是無效的。
而端到端自動駕駛在一定程度上就給了 Scaling Law 發(fā)揮的余地,這符合目前人工智能的大趨勢。
在傳統(tǒng)的技術(shù)棧解決問題上,不論多么復(fù)雜的 Corner Case 都需要工程師們,用非常抽象的方式將場景描述清楚,收集數(shù)據(jù)然后標(biāo)注,解決問題,然后驗證。
但是實際上場景浩如煙海,很多任務(wù)非常瑣碎,以單點突破的方式幾乎沒有可能完全解決。
所以有些公司的場景待解決庫里面會將重點的安全問題先處理,而小頻率的體驗問題會之后處理,而這些小頻率的體驗問題,可能就決定了,這個場景的處理是否類人。
例如,紅綠燈前的減速度是否絲滑,是否是根據(jù)當(dāng)時的車道線和交通參與者做的實時判斷?
6 月 7 日,在上海人工智能實驗室主辦的端到端研討會上,前段時間離職加入小米的消息引發(fā)廣泛關(guān)注的王乃巖提出:
端到端可以將很瑣碎的任務(wù),用人類的駕駛習(xí)慣進(jìn)行統(tǒng)一的監(jiān)督,降低開發(fā)成本,與可解釋的傳統(tǒng)技術(shù)棧結(jié)合,可能可以帶領(lǐng)我們走向 L4 甚至 L5。
03 端到端自動駕駛的難點
我們都知道神經(jīng)網(wǎng)絡(luò)是黑盒系統(tǒng),目前其實也沒有辦法去控制神經(jīng)網(wǎng)絡(luò)內(nèi)部發(fā)生了什么,而這天然與自動駕駛要求的安全性和可靠性相悖。
在傳統(tǒng)的技術(shù)棧中,如果遇到了一個問題,是可以通過分模塊的方式找到出問題的部分,例如感知層給的目標(biāo)的位置不對、規(guī)劃給的軌跡不好。
但是端到端系統(tǒng)這些方式就失效了。
更好的問題歸因優(yōu)化和驗證系統(tǒng)迫在眉睫。
如何找到合適的數(shù)據(jù)
我們可以將同樣基本是黑盒的感知系統(tǒng)推廣到整個自動駕駛系統(tǒng)上。
以前感知如果出了問題應(yīng)該怎么做,這里舉一個非常典型的 Corner Case, 公交車上廣告牌的人形圖案,這個問題特斯拉、理想都爆出過誤識別新聞。
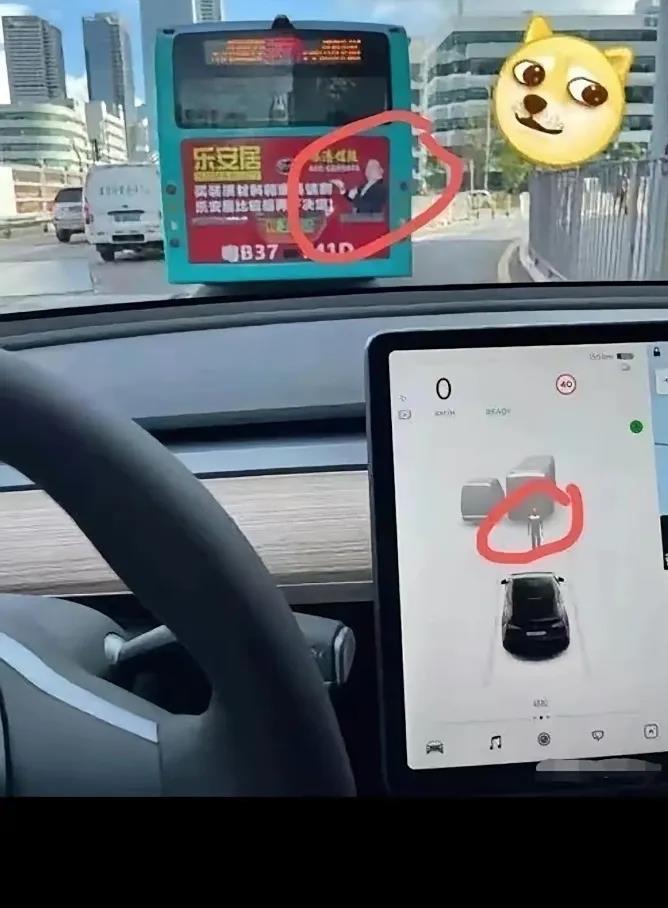
應(yīng)該如何解決這個問題?
挖掘足夠的的公交車上廣告牌的人形圖案數(shù)據(jù),扔給神經(jīng)網(wǎng)絡(luò)進(jìn)行訓(xùn)練,不斷優(yōu)化感知系統(tǒng),規(guī)劃和控制部分可以保持不變。
那么再進(jìn)一步,已經(jīng)是端到端系統(tǒng)了,如果現(xiàn)在結(jié)果是車輛誤剎。
那么問題的歸因就成了一個巨大的問題,因為沒有辦法馬上知道,是因為這個人形圖案帶來的 BUG,也就無法去對應(yīng)尋找數(shù)據(jù)。
即使找到了對應(yīng)的問題,尋找特定的數(shù)據(jù)也是巨大工程,需要在數(shù)據(jù)閉環(huán)系統(tǒng)中找到相似的人形公交視頻和人類駕駛數(shù)據(jù),再進(jìn)入端到端系統(tǒng)進(jìn)行訓(xùn)練。
那么新的問題又出現(xiàn)了,如何驗證問題已經(jīng)修復(fù)并且性能不回退呢?
如何驗證端到端自動駕駛系統(tǒng)
我們知道傳統(tǒng)的自動駕駛技術(shù)棧通過仿真虛擬進(jìn)行大規(guī)模驗證得出結(jié)論后,可以上車進(jìn)行實車測試。
而這里最重要的區(qū)別是,仿真的驗證。
在傳統(tǒng)的技術(shù)棧中,可以將每個模塊分開來驗證的,感知和規(guī)劃可以分別用數(shù)據(jù)在云上大規(guī)模驗證,每個團(tuán)隊都會有一個數(shù)據(jù)庫,每次新系統(tǒng)上線會將數(shù)據(jù)喂到新系統(tǒng)里面進(jìn)行大規(guī)模驗證。
這是之前的經(jīng)驗。
但是這里有兩個問題:
- 大部分團(tuán)隊的驗證方式是開環(huán)驗證,也就是并沒有與環(huán)境產(chǎn)生任何交互,只驗證輸入和輸出鏈路。
- 大部分團(tuán)隊對感知的驗證還無法用純虛擬的方式進(jìn)行,需要實車數(shù)據(jù)才可以完成。
而這與端到端自動駕駛是相悖的。
端到端駕駛系統(tǒng)在上車跑之前,必須要用虛擬的方式全局驗證通過,否則上車跑通無異于天方夜譚。
那么就涉及到一個非常好的可以模擬所有感知輸出的自動駕駛模擬器,而且能夠在這個模擬器里面模仿所有的交通參與者的交互信息。
即為了保證系統(tǒng)在真實世界的安全性,我們需要在虛擬世界中將系統(tǒng)充分驗證。
前文提到的 Carla 在一定程度上可以滿足學(xué)界的需求,但是場景的單一和渲染的質(zhì)量,離業(yè)界的要求依然想去甚遠(yuǎn)。

其實不難看到,端到端自動駕駛依然依賴原有的自動駕駛開發(fā)工具鏈,優(yōu)秀的數(shù)據(jù)閉環(huán)工具用來收集數(shù)據(jù),優(yōu)秀的自動駕駛仿真系統(tǒng)用來驗證,而這大部分團(tuán)隊幾乎都沒有。
從這個角度來看,端到端自動駕駛無法進(jìn)行彎道超車。
寫在最后
雖然著名反 OpenAI 人工智能專家楊樂昆認(rèn)為,現(xiàn)有的 LLM 盡管在自然語言處理、對話交互、文本創(chuàng)作等領(lǐng)域表現(xiàn)出色,但其仍只是一種「統(tǒng)計建模」技術(shù)。
通過學(xué)習(xí)數(shù)據(jù)中的統(tǒng)計規(guī)律來完成相關(guān)任務(wù),本質(zhì)上并非具備真正的「理解」和「推理」能力。
而這個理論似乎放在端到端自動駕駛上也成立,相似的是最近港大的著名學(xué)者馬毅提出:如果相信只靠 Scaling Laws 能實現(xiàn) AGI,你該改行了。
那么似乎我們也可以說:如果相信只靠端到端就能實現(xiàn) L5,那么你該改行了。
不過,我們目前看到最有希望的一條路已經(jīng)擺在了我們面前,雖然這條路看不到是否能夠通向終點,這條路似乎也沒有那么簡單,路上充滿了很多不確定性,抵觸的聲音不絕于耳。
但是特斯拉已經(jīng)向我們示范了這條路的巨大潛力。
所以,我們?yōu)槭裁床蝗L試呢?
轉(zhuǎn)自焉知汽車
