
而隨著電子電氣架構(gòu)繼續(xù)向跨域融合演進,智能座艙芯片算力同步提升,這些主機廠緊跟大算力芯片帶來的艙駕融合熱度,其研發(fā)重點正在從原來的行泊一體向艙駕一體進階。實際上,艙駕融合可以說是真正的跨域融合,也是電子電氣架構(gòu)進一步向中央集成式邁進的關(guān)鍵一步,同時也符合降本增效的行業(yè)趨勢。
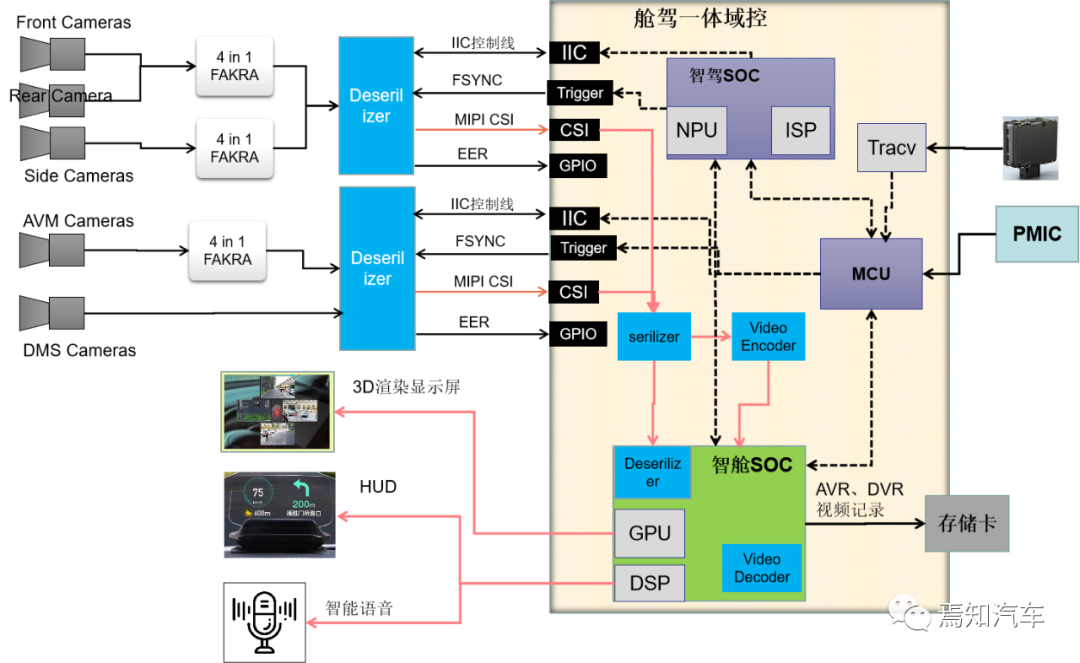
所謂艙駕一體,就是將座艙域和智駕域集成到一個高性能計算單元中,同時支持智能駕駛和智能座艙功能,參照當前比較典型的設(shè)計用例就是將座艙域芯片+駕駛域芯片+高效的CPU進行集成的艙駕一體化域控。相較于行泊一體和艙泊一體,這種架構(gòu)的集成度更高,當然對硬件的要求也隨之升高。
艙駕一體系統(tǒng)架構(gòu)的難度在哪里?
1、集中式控制難度
在集中式架構(gòu)中,智能座艙域控制器和智能駕駛域控制器都被集成在一個中央控制單元中。從軟件角度來看,由于“艙駕一體化”集成系統(tǒng)所驅(qū)動的整體軟件架構(gòu)迭代,可以獲得更多的功能或者更好的功能體驗。然而,這需要單獨適配軟件應(yīng)用中心的中央控制單元負責整個車輛系統(tǒng)的控制和協(xié)調(diào)。基于此,這里就不得不提到控制軟件的基石:操作系統(tǒng)了。作為無論是底層還是上層應(yīng)用算法的基礎(chǔ),操作系統(tǒng)的重要性不言而喻。
然而,集中式智駕和智艙域控需要解決在智能系統(tǒng)控制中不同軟件開發(fā)平臺的兼容性問題。因為,對于智艙域來說,操作系統(tǒng)是基于QNX或Andriod語言編寫的,而智駕域的操作系統(tǒng)大多基于Linux或C++語言。如果是在域控中不同的芯片上部署不同的操作系統(tǒng),其運行策略就需要考慮如何設(shè)計相應(yīng)的調(diào)度接口來滿足其兩種系統(tǒng)下的應(yīng)用程序調(diào)度和通信。
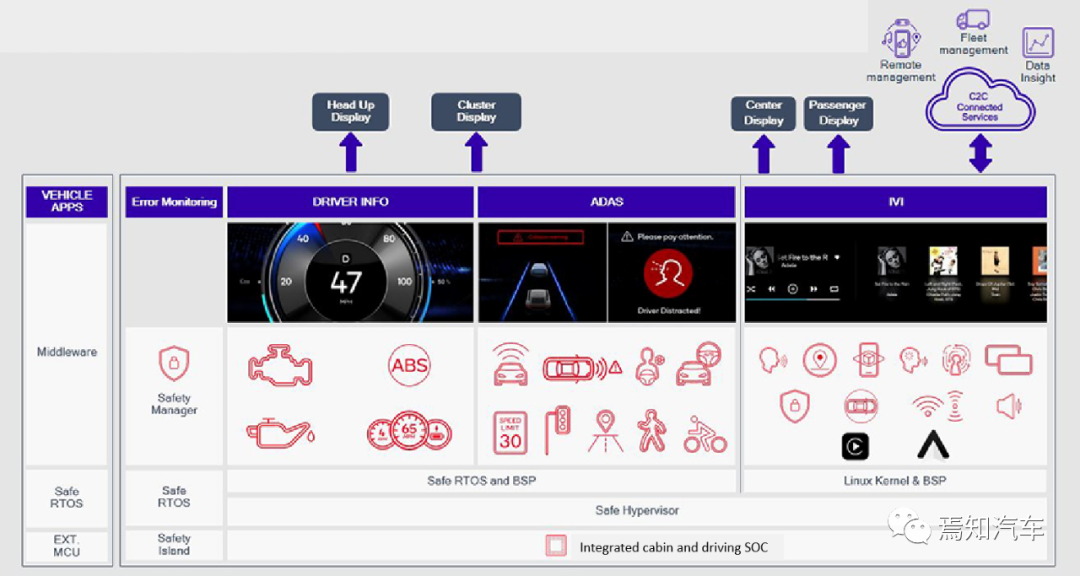
可以說,上層生態(tài)的遷移以及軟件適配的復(fù)雜度和難度將隨著智能駕駛域和座艙域融合度的增加而顯著增加,開發(fā)成本也會增加。
2、硬件設(shè)計難度
從硬件角度看,“座駕一體化”可以提高傳感器、芯片等硬件的復(fù)用率,降低成本。無論是采用一盒、一板還是一芯片方案,相比目前智能駕駛領(lǐng)域和座艙領(lǐng)域的兩盒兩芯片方案,在硬件方面都可以很好的減少域控和芯片的投入,同時也可以減少域之間的線束數(shù)量。通過將智能座艙和智能駕駛的功能集成在一個中央控制單元中,減少了電氣線束和接口的數(shù)量,簡化了系統(tǒng)的架構(gòu)。可以說集中式架構(gòu)可以降低系統(tǒng)的復(fù)雜性和維護成本。
然而,艙駕一體芯片設(shè)計面臨著較大的挑戰(zhàn),例如設(shè)計復(fù)雜度、功耗、散熱等問題。以功耗為例,單就智駕域控而言,為了滿足其功耗和散熱的要求,其要求的芯片制程就已經(jīng)開始向下探到接近于14nm甚至7nm了。而再加上智艙芯片,特別是在圖形渲染上也會占用大量的運算資源。兩者結(jié)合起來,對于合適的芯片選型要求就更高了。
3、數(shù)據(jù)傳輸及處理
艙駕一體芯片的優(yōu)勢在于集成度高,可以減少系統(tǒng)的復(fù)雜性和成本。通過一個芯片實現(xiàn)座艙控制和駕駛控制的整合,可以提供更高度的系統(tǒng)一致性、響應(yīng)性和實時性。集中式架構(gòu)通過內(nèi)部網(wǎng)絡(luò)傳輸各個子系統(tǒng)的數(shù)據(jù)。智能座艙域控制器和智能駕駛域控制器之間可以通過高速數(shù)據(jù)總線或以太網(wǎng)等方式進行數(shù)據(jù)交互和共享。
然而,數(shù)據(jù)傳輸介質(zhì)和標準規(guī)格上,智駕和智艙的要求也略有不同。舉個例子,對于視頻處理這一常規(guī)的處理而言,智駕系統(tǒng)需要接入的視頻格式要求通常是像RGB這類原始視頻,且要求幀率一般較低。因此,在視頻傳輸介質(zhì)選型上,智駕系統(tǒng)通常會選擇MIPI或者PCIe這類并行效率高,且較為穩(wěn)定的介質(zhì)。另一方面的,對智艙而言,則更加傾于傳輸方便于壓縮傳輸?shù)脑家曨l流(如YUV),或者是對原始視頻流進行壓縮處理后的HEVC/H.264視頻。且智艙對于顯示效果會更加傾向于還原實際場景,這樣就必然要求其幀率也是足夠高,比如流媒體視頻就是個典型的例子。
那么問題就來了,如果是既用于智駕又用于智艙的視頻將如何在同一個域控中被處理,比如部分視頻抽幀,視頻時間同步等問題就就會對艙駕一體域控的數(shù)據(jù)傳輸及處理能力提出新的要求。
4、系統(tǒng)一致性
由于智能座艙和智能駕駛都由同一個中央控制單元控制,因此系統(tǒng)的一致性和兼容性會得到更好的保證。比如,集中式架構(gòu)通過集中處理和控制,可以更高效地處理各種輸入數(shù)據(jù)并做出相應(yīng)的決策和控制,實現(xiàn)較好的實時性和響應(yīng)性控制。
需要注意的是,集中式架構(gòu)雖然具有一些優(yōu)點,但也有一些潛在的缺點。
由于智駕與智艙所處理的是不同的功能模塊,一個偏駕駛性控制,另一個偏交互性控制,兩者無論是在功能安全還是信息安全上都有著完全不同的層次需求。例如,就功能安全而言,智能駕駛領(lǐng)域與座艙領(lǐng)域功能安全要求也各有不同,導致滿足車輛監(jiān)管要求也隨之增加。此外,集中式架構(gòu)可能存在單點故障的風險,即如果中央控制單元發(fā)生故障,整個系統(tǒng)都會受到影響。此外,集中式架構(gòu)可能面臨處理大量數(shù)據(jù)安全的挑戰(zhàn),需要考慮處理能力限制、數(shù)據(jù)傳輸?shù)膸捪拗啤⒁约皵?shù)據(jù)入侵風險可能導致的全盤崩塌。
因此,在實際設(shè)計中,短期內(nèi)艙駕一體域控難以實現(xiàn)平臺化、標準化、規(guī)模化。為了可以更好地協(xié)同工作,需要實現(xiàn)更高級別的軟硬件模塊整合。同時,需要綜合考慮系統(tǒng)的可靠性、性能和復(fù)雜性等因素來選擇合適的架構(gòu)。
“艙駕一體”實現(xiàn)推手——高算力芯片計算平臺
眾所周知,座艙芯片主要的計算任務(wù)是圖形處理,包括渲染等,對GPU的算力要求高。提到這個就不得不提當前比較火熱的通過智駕感知輸出+地圖的全場景渲染需求了。對于這樣的場景重構(gòu)需求而言,智艙處理能力的要求不僅僅是在傳統(tǒng)的2D渲染上,更多的則是在其3D渲染上。想想需要勾勒和重現(xiàn)的那些3D模型,以及為了實現(xiàn)渲染效果的真實性,這樣的處理過程要求是并行的、實時的,不難看出這將是一個十分龐大的工作量。
相較于智艙而言,智駕芯片主要的計算任務(wù)是深度學習,對NPU的算力要求高。那么如果要實現(xiàn)艙駕一體,那就必須同時解決GPU算力和NPU算力問題。艙駕一體化需要逐步打通智能駕駛域與座艙域之間的部門圍墻,推動組織架構(gòu)一體化以提高效率。同時還要充分考慮如下一些要素的配合才行。
基于此,用于座艙和智駕的SOC芯片一般包含GPU、CPU、NPU、ISP等不同的IP模塊。在做艙駕一體的芯片選型時需要充分考慮綜合算力、帶寬、外設(shè)、內(nèi)存、能效比、成本等多方面因素。同時,除開考慮芯片本身的性能外,還要綜合考慮芯片外圍生態(tài),相關(guān)芯片的開發(fā)工具鏈,各芯片相互之間的適配性的要素,軟件模塊之間調(diào)用和通信關(guān)系等。
實際上,當前還沒有一款真正能夠由一家生態(tài)實現(xiàn)的完整的艙駕一體大集成式芯片。當然,當前國內(nèi)外已有一些芯片廠商看到了艙駕一體的發(fā)展商機,開始花大力氣開發(fā)這樣一款既能滿足智駕又能滿足智艙的芯片,期望能在這一領(lǐng)域第一個搶占市場。比較典型的有智駕和智艙的龍頭老大,“英偉達”和“高通”。
筆者看來,英偉達是一家充滿野性的芯片公司,早在很久以前,應(yīng)為已經(jīng)牢牢占據(jù)了智駕領(lǐng)域的半壁江山,已被廣泛應(yīng)用的Orin系列早已經(jīng)為業(yè)界所熟知,而該公司研發(fā)大算力芯片的腳步卻從未停止。在去年9月,英偉達又重磅發(fā)布了大算力芯片命名為Drive Thor的芯片。該芯片最大的特點就是實現(xiàn)座艙域、駕駛域的融合,同時可支持多計算域間隔離,這樣,就可以很好的滿足將輔助駕駛、自動泊車、信息娛樂、DMS等多種功能整合在同一塊芯片中運行。且公司已經(jīng)在不少場合官宣,Thor芯片將在2025量產(chǎn)。

另一方面,坐穩(wěn)智艙處理芯片廠商的龍頭老大——高通公司也不甘示弱。其在2023年1月推出的全新驍龍Ride Flex系統(tǒng)級芯片和新的自動駕駛平臺(Snapdragon Ride)可以完美的融合了高通的數(shù)字化駕駛艙和高級駕駛輔助平臺上,有助于在相同的硬件(Ride Vision)上協(xié)同處理智駕和智艙的所有應(yīng)用場景。
而以上提到的兩家王者級別的芯片(NVIDIA的Drive Thor和高通Snapdragon Rideflex)其算力也是十分驚人的,據(jù)官方提前爆出的資料顯示,GPU算力均超過2000TOPS。
當然,為了跟上時代洪流,國內(nèi)的多家芯片供應(yīng)商也開始跟著“卷”起來。黑芝麻作為其中一家典型的芯片公司,也早在2023年4月宣布開發(fā)一款覆蓋座艙、智駕、網(wǎng)關(guān)等不同領(lǐng)域的跨域計算場景的芯片——“C1200”。雖然,目前距離艙駕一體芯片真正落地還有一段時間,但是,黑芝麻的此番官宣也是比較吸睛的。
艙駕一體系統(tǒng)架構(gòu)的設(shè)計
我們知道,智能汽車的中央控制單元采用異構(gòu)單元設(shè)計,一般由 SoC 和 MCU 構(gòu)成。SoC、MCU 根據(jù)應(yīng)用的功能和性能要求,可以增加多個同構(gòu)/異構(gòu) SoC、MCU 形成分布式計算硬件架構(gòu)。對于艙駕一體域控制器而言,各個芯片系統(tǒng)主要通過總線和網(wǎng)絡(luò)進行連接,實現(xiàn)數(shù)據(jù)交互。為滿足智駕域與座艙域在智能駕駛和智能交互中所需求的更高算力需求,通常需要采用多個型號的 SoC 分布式計算單元,來實現(xiàn)算力翻倍。
智能駕駛中的艙駕一體芯片是指集成了座艙控制和駕駛控制功能的芯片。它是一種高度集成的芯片解決方案,旨在實現(xiàn)智能座艙和智能駕駛系統(tǒng)的整合。艙駕一體芯片的設(shè)計目標是在一個芯片上集成座艙控制和駕駛控制相關(guān)的功能模塊。實現(xiàn)的算力類型包括但不限于AI 算力、邏輯算力、GPU 算力、DSP 算力。這些算力資源需要實現(xiàn)的用途包括感知運算、融合運算、預(yù)測篩選運算、規(guī)劃運算、定位運算、地圖運算、拼接渲染運算、車控運算等。通過集成這些功能,艙駕一體芯片可以實現(xiàn)對車輛的全面控制,并提供更高級別的智能駕駛體驗。
對于艙駕一體域控設(shè)計而言,根據(jù) SoC 和 MCU 單元組合后的架構(gòu)設(shè)計,可分為 4 種常見架構(gòu)形態(tài)。
(1)形態(tài) 1:SoC 和 MCU 完全獨立,一般通過 SPI 總線,實現(xiàn)通信互聯(lián);
(2)形態(tài) 2:雙 SoC 通過高速總線 PCIe 級聯(lián),實現(xiàn)高帶寬數(shù)據(jù)交互,GPIOs 實現(xiàn)低速信號通信,兩 SoC 分別通過 SPI 接口和 MCU 通信;
(3)形態(tài) 3:三個或三個以上的 SoC,通過 PCIe 連接到同一個 PCIe Switch 網(wǎng)關(guān)芯片,實現(xiàn)SoC 間高帶寬數(shù)據(jù)交互,同時各 SoC 分別通過 SPI 接口和 MCU 通信;
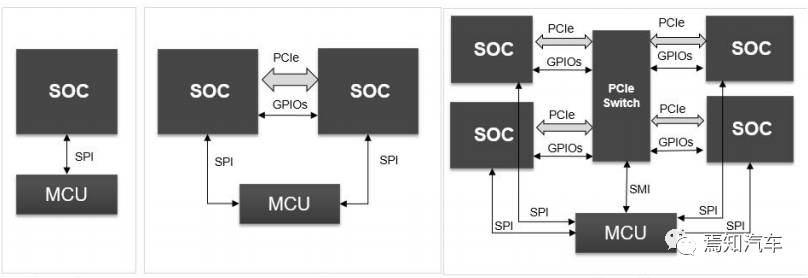
如上1、2、3這類型中央控制器的設(shè)計主要取決于新所選型的芯片能力能否完全適配上對于對應(yīng)的算力需求。
從所要實現(xiàn)的智駕系統(tǒng)和座艙系統(tǒng)的分級標準上進行芯片選型是比較合理的一種方式。比如,針對L2級以下功能,通常智駕和智艙是可以選擇低算力平臺的一些芯片的。因為從智駕上講,50Tops+50KDMIPS已經(jīng)足足夠已,而智艙而言,則基本就是一些常規(guī)的2D圖像顯示和聲音報警,甚至連像DMS這樣的處理單元都用不上的。因此,這樣的智艙芯片可能連AI算力需求都是極低的。
然而,隨著自動駕駛系統(tǒng)的升級,比如L2+以上的系統(tǒng),在硬件選型上則更傾向于大算力、存儲、通信接口更加豐富的芯片了。
(4)終極形態(tài):MCU 集成在 SoC 內(nèi)部,通過芯片內(nèi)部的 IPC 接口,實現(xiàn)進程通信和數(shù)據(jù)交互;
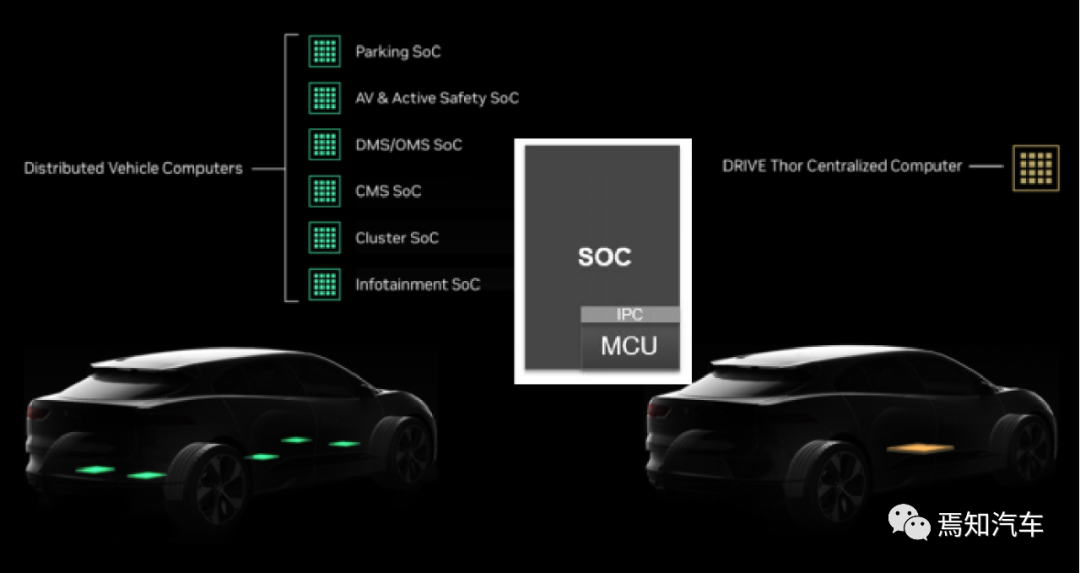
以英偉達的DRIVE Thor為例,該芯片支持多域計算,隔離自動駕駛和智能座艙相關(guān)功能。DRIVE Thor 的性能高達 2,000 teraflops的 FP8 精度,允許在不犧牲精度的情況下過渡到 8 位。將智能功能(包括自動駕駛和輔助駕駛、智能泊車、駕駛員和乘員監(jiān)控、數(shù)字儀表盤、車載信息娛樂 (IVI) 和后座娛樂)統(tǒng)一到單一架構(gòu)中,這樣可以提高效率并降低總體系統(tǒng)成本。通常,數(shù)十個電氣控制單元分布在車輛各處,為各個功能提供動力。
DRIVE Thor 作為第一個 NVIDIA GPU 中 Tensor Core 的新組件中的推理變壓器引擎 AV 平臺。借助該引擎,DRIVE Thor 可以將 Transformer 深度神經(jīng)網(wǎng)絡(luò)的推理性能提高高達 9 倍,對于支持與自動駕駛相關(guān)的大量復(fù)雜的人工智能工作負載至關(guān)重要。
同時,DRIVE Thor 首次在 NVIDIA Hopper? 多實例 GPU 架構(gòu)中引入的尖端 AI 功能,以及 NVIDIA Grace? CPU 和 NVIDIA Ada Lovelace GPU。這具有對圖形和計算的 MIG 支持,獨特地使 IVI 和高級駕駛員輔助系統(tǒng)能夠運行域隔離,從而允許并發(fā)時間關(guān)鍵流程不間斷地運行。
因此,借助 DRIVE Thor,域控開發(fā)端可以有效地將許多功能整合到單個片上系統(tǒng) (SoC) 上,從而緩解供應(yīng)限制并簡化車輛設(shè)計開發(fā),從而顯著降低成本、減輕重量并減少電纜數(shù)量。
總結(jié)
未來隨著智能駕駛技術(shù)的普及,智能座艙所能發(fā)揮的空間也就越大,艙駕一體化逐漸成為發(fā)展趨勢,終極目標是將座艙域、智駕域、動力域、底盤域、車身域進行跨域大融合。而實現(xiàn)這一目標的前提是先做分布式融合后建立一定的局部跨域融合處理,即先將部分域的功能集成到一個高性能計算單元內(nèi),再逐漸聚合更多的功能域。隨著大算力芯片的研發(fā)落地,后續(xù)的艙駕一體甚至是整車一體化控制都會逐步實現(xiàn)。
轉(zhuǎn)自焉知汽車
